
Innhold:
Mine 10 beste memoQ-triks
I anledning av at jeg denne uken kjøpte min første lisens til memoQ, tenkte jeg å liste opp noen tips og triks jeg bruker når jeg arbeider i dette CAT-verktøyet. Listen er nok mest interessant for deg som allerede har kjennskap til verktøyet. For deg som ikke kjenner til det og lurer på hva det er, vil jeg forklare det i neste avsnitt.
Hva er memoQ?
memoQ er et såkalt CAT-verktøy (Computer Assisted Translation). CAT-verktøy er i bunn og grunn en tekstbehandler som Word eller Notepad, men spesielt for oversettelsesarbeid. Det finnes en rekke ulike CAT-verktøy der ute, men i dag er det vel bare memoQ og Trados Studios som kan betegne seg selv om «bransjestandard».
Grunnen til at man bruker et CAT-verktøy, i stedet for å jobbe i en vanlig tekstbehandler, er at de samler en rekke praktiske funksjoner.
-
De deler opp teksten i segmenter, hvilket gjør det enklere å jobbe raskt.
-
De gir deg en todelt visning med kildetekst og måltekst, slik at du har alt i synsfeltet.
-
De viser deg masse kontekst: treff i tidligere oversettelser, treff i ordbøker og treff i kundens egen terminologilister. De lar deg også bearbeide disse ressursene.
-
De fleste har også innebygd parsing av alle mulige filformater. I memoQ kan du importere alt fra HTML til PDF, uten å gå gjennom et mellomledd.
-
Sist, men ikke minst legger de til rette for enkel distribusjon av tekster og ressurser. Derfor brukes de av svært mange oversettelsesbyråer.
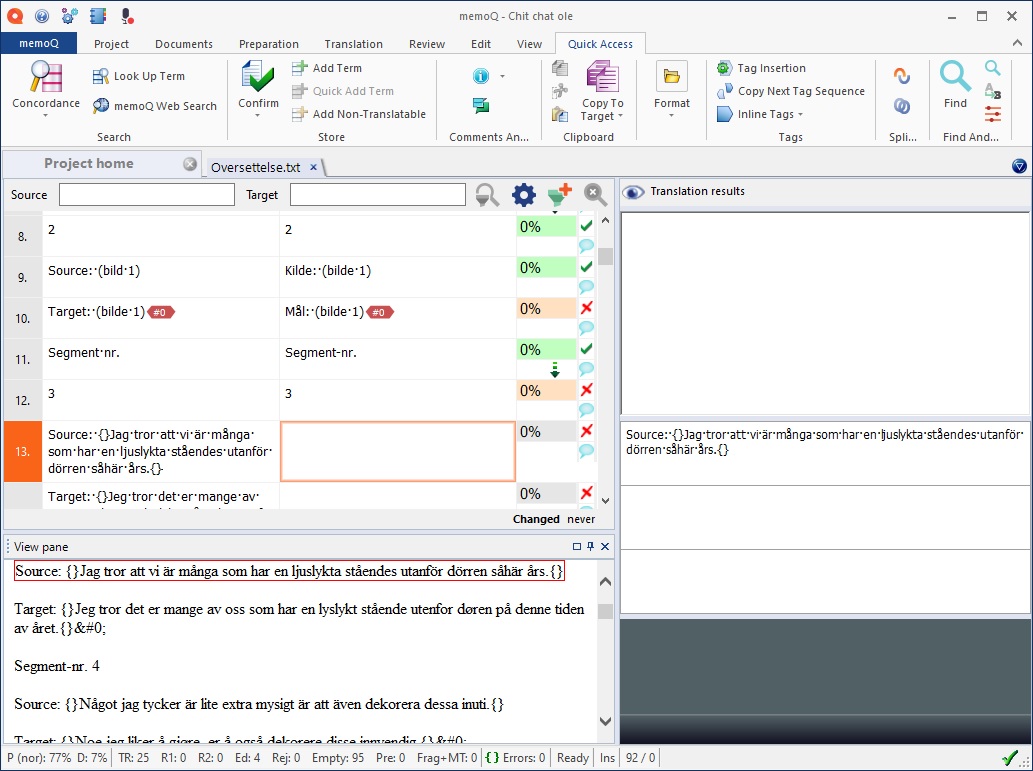
Slik ser en vanlig visning i memoQ ut. Tekstfeltet er delt mellom kildetekst og måltekst. Nederst ser man en forhåndsvisning av det ferdige dokumentet. Til høyre vil man se informasjon fra ordlister og oversettelseminne.
Selv synes jeg memoQ er et veldig godt verktøy. Det har mye å si at man liker programmet man jobber i. Jeg arbeider også mye i det eldre CAT-verktøyet Transit NXT, og det har en del åpenbare mangler som gjør at jeg alltid savner memoQ.
Likevel tok det meg litt tid å bruke memoQ på en effektiv måte. Programmet har en rekke skjulte funksjoner. Mye har jeg funnet selv ved å eksperimentere inne i programmet, mens andre ting har jeg funnet ved å lese memoQs offisielle dokumentasjon.
Her kommer mine 10 tips og triks for å jobbe i memoQ!
1. Hold det aktive segmentet i midten
Noen ganger er det enkleste det viktigste. Noe av det som kan drive meg til vanvidd i de fleste andre tekstbehandlingsverktøy, er at den aktive linjen man skriver på alltid havner nederst. Dette er også standard i memoQ. Når man bare ser linjene over det aktive, har man jo bare halve konteksten i synsfeltet. I verktøyraden øverst, gå til
View > Active Row > In the middle
Da er det aktive segmentet alltid i midten – og man har alltid oversikt over teksten umiddelbart før og etter.
2. Bevegelser over korte avstander med tastaturet
memoQ gir heldigvis en noen muligheter for å raskt bevege seg rundt i området rundt det aktive segmentet.
-
Denne bør være velkjent for de fleste, men jeg lister den opp for det: bruk
Ctrl + Piltast venstre/høyrefor å flytte markøren ord for ord. -
Med
Ctrl + PgUpogCtrl + PgDownkan man flytte markøren til starten eller slutten av et segment. Praktisk om det ene ordet du vil endre på befinner seg til slutt. -
Med
Alt + Piltast OppellerAlt + Piltast Nedkan man hoppe et segment opp eller ned. Merk at kun piltastene uten Alt kun flytter deg rad for rad inne i segmentet. -
Med
PgUpogPgDownkan man skrolle opp eller ned et helt skjermbilde. -
Ctrl + Amarkerer hele segmentet. Nyttig for å slette all forhåndsoversatt tekst. (Ctrl + Shift + Amarkerer alle segmenter).
Disse kommandoene er supre til å f.eks. hoppe litt bakover for å endre et ord du ikke er fornøyd med, eller til å raskt skifte ut noen ord i en eksisterende tekst.
3. Bruk Auto-Propagation
Det vil nesten alltid lønne seg å ha på Auto-Propagation. Funksjonen gjør at alle segmenter som er 100% like og befinner seg under det segmentet du arbeider med, automatisk blir godkjent når du kvitterer med Ctrl + Enter . I kombinasjon med Go To Next (se neste tips) kan man hoppe raskt og effektivt gjennom teksten.
Men Auto-Propagation gir ikke mening i situasjoner der segmenteringen ikke er vellykket. Om segmentene har blitt delt opp feil, vil det ofte ikke gi mening at oversettelsene skal autopropageres gjennom hele filen. Da kan dette slås av i verktøyraden under
Translation > Translation Settings > Auto-Propagation
4. Bruk Go To Next flittig
Ctrl + G står for «Go To Next», og det er en viktig tastekombinasjon i memoQ. Denne gjør at du automatisk hopper til neste segment som samsvarer med et forhåndsdefinert filter. Filteret stiller du inn med Ctrl + Shift + G
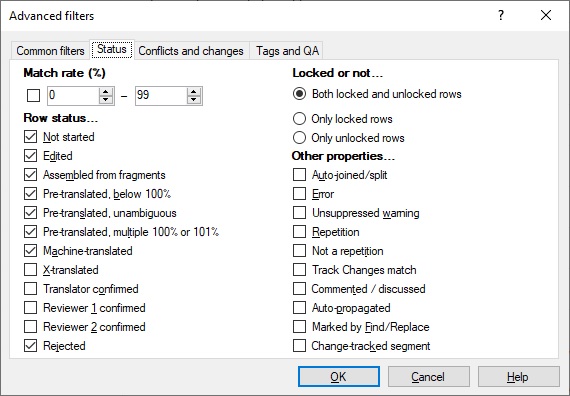
Dette er filtermenyen til memoQ. Den brukes bl.a. av Go To Next til å hurtigfiltrere alle segmenter
Man bruker tastekombinasjonen stort sett for å hoppe til neste «ubehandlede» segment.
Når jeg oversetter en fil pleier jeg å bruke innstillingen i bildet ovenfor. Når jeg korrekturleser det noen andre har oversatt, pleier jeg å kun huke av for «Translator confirmed».
Med Ctrl + Shift + G kan man også huke av for «Automatically Jump after Confirmation». Det gjør at du automatisk hopper til neste ubehandlede segment etter å ha kvittert et segment med Ctrl + Enter. I kombinasjon med Auto-Propagation gjør det at man kan jobbe veldig raskt, da man automatisk alltid hopper over de segmentene som er gjentakelser.
5. Sorter filen med filtre
Filtermenyen i forrige punkt kan også brukes til å filtrere segmenter. Trykk på filtersymbolet til høyre over målteksten (ved siden av tannhjulet) for å få opp samme meny.
Jeg pleier for eksempel å filtrere ut alle ubehandlede segmenter om det er en veldig stor fil med mye forhåndsoversettelser. Man kan også sortere etter Match Rate. I starten av en stor jobb kan det være nyttig å få unna segmenter med høy match rate for å få et mer realistisk bilde av størrelsen på filen.
Om prosjektlederen har låst segmenter, kan disse også filtreres bort her.
6. Bevegelser over lange avstander med hurtigfiltre
Når jeg har gått i gjennom filen en gang, pleier jeg å bruke hurtigfiltrene for å hurtig finne tilbake til enkelte segmenter. De to tekstfeltene over henholdsvis kildeteksten og målteksten kan brukes til å filtrere alle segmentene etter ord. Dette er f.eks. nyttig i følgende scenario:
-
du har vært teksten igjennom, og du innser at oversettelsen din av frasen «apply the principles» ikke var så bra. Dette var en frase som gikk igjen ofte, og du har oversatt den litt ulikt hver gang. Da kan du skrive inn de tre ordene i søkefeltet over kildeteksten, og du vil kun stå igjen med de segmentene hvor denne frasen forekom i kildeteksten.
-
samtidig husker du at kunden ikke ønsker å bruke forkortelsen «app», men ønsker å skrive det litt mer formelt som «applikasjon» eller «program», avhengig av hva som passer. Da kan du filtrere etter «app » (med mellomrom) i målteksten, og så gå igjennom disse segmentene.
Jeg har blitt veldig glad i å bruke filtrene aktivt for å bevege meg raskere tilbake gjennom det jeg allerede har oversatt. I mange situasjoner er filtrene også bedre enn search and replace, siden de ikke er så umiddelbare. Du får tid til å se gjennom segmentene på nytt og leke litt med dem før du lander på en ny oversettelse.
Men, vi kommer så klart ikke utenom å nevne…
7. Search and replace for life
Det viktigste verktøyet i ethvert tekstbehandlingsprogram.
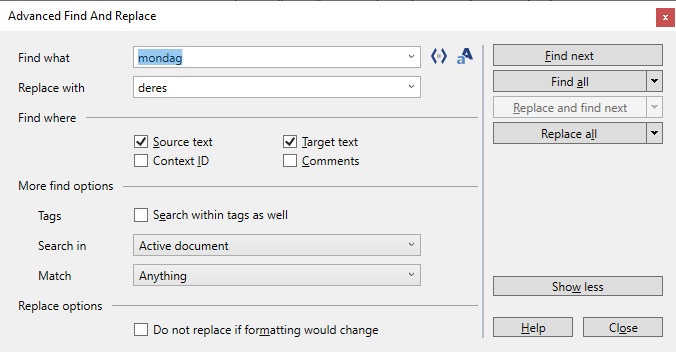
Varianten i memoQ er faktisk veldig god. Man kan velge mellom kildetekst og måltekst, og man kan også søke i tagger. Man kan søke case-insensitive og -sensitive. Det fungerer veldig bra å erstatte i sensitive-modusen, memoQ klarer som regel å bruke store og små bokstaver riktig. Man har også mulighet til å trykke «Find all» for å se alle funnene i et eget vindu.
Om man trykker på de to «større enn», «mindre enn»-symbolene øverst (< >), har memoQ også støtte for regular expressions. Mer om det senere.
PS: som i mange andre programmer kan man trykke Ctrl + H for å åpne Search and replace direkte.
8. Versjonskontroll
Jeg har tidligere skrevet et blogginnlegg om versjonskontrollen i memoQ.
Kort sagt lagrer memoQ mye metainformasjon om tidligere versjoner av samme dokument. Dette kan man bruke til sin fordel. For eksempel kan man eksportere alle endringer til en Word-fil med tracked changes for å dele endringer med andre lingivster. Man kan også filtrere på endringsdato og se tidligere versjoner av enkeltsegmenter. Det er veldig nyttig om du vil se hvordan teksten har utviklet seg.
9. Fjern slitsom markup med regex tagger
Markup vil si kodetegn som f.eks. «\n» (linjeskift), «<br>» (også linjeskift), « » (hardt mellomrom) og så videre. Dette er kode som f.eks. skal tolkes av en nettleser for å markere teksten på en bestemt måte. F.eks. skrives fet skrift slik i HTML: <strong>fet skrift</strong>
memoQ har god støtte for å filtrere bort markup, slik at man som oversetter kan konsentrere seg om den faktiske teksten. Noen ganger sniker det seg likevel med noen varianter. Jeg har f.eks. lagt merke til at «\n» sjelden blir filtrert bort. Om teksten ser slik ut, kan det bli slitsomt:
Kjære kunde\n\nVi ønsker å gjøre dere oppmerksomme\npå at det ikke er mulig å\nbetale med kort.\n\nTakk for forståelsen.\n\nmvh kundeservice.
Hver «\n» er viktig å få med, fordi den representerer et linjeskift. Men i sin nåværende form er det tungvint å se hvor ordene begynner og slutter. Dessuten vil vi bruke mye tid på stavekontroll, siden den vil reagere på nesten annethvert ord. Det er bortkastet tid om teksten er på 10 000 ord eller mer.
Med regex-tagger kan man låse hver forekomst av «\n» inn i en tagg. I memoQ representeres en slik tagg som en liten rød blokk som ikke kan endres på. Den teller ikke som et ord. Programmet reagerer dessuten dersom taggen mangler eller ikke står i riktig rekkefølge.

Regex-tagger finner man i verktøyraden under
Preparations > Regex Tagger
10. Regular expressions i memoQ
Det siste punktet er at memoQ er det eneste CAT-verktøyet jeg kjenner til som har god støtte for bruk av regular expressions, eller regulære uttrykk på godt norsk.
Jeg vil skrive egentlig skrive et eget blogginnlegg om dette temaet, men i korte trekk kan man søke etter mønstre uten å kjenne det nøyaktige innholdet.
Dette er et kjempenyttig verktøy som kan brukes i mange av memoQ sine filtrerings- og søkefunksjoner.
-
I Regex tagger brukes det til å låse tekst inn i tagger, slik jeg viste i punkt 9.
-
I hurtigfilteret kan man også filtrere etter regulære uttrykk. Klikk på tannhjulet for å aktivere.
-
I search and replace kan man trykke på «<>»-symbolet for å bruke søk og erstatt med regulære uttrykk.
Noen raske eksempler på hvilke superkrefter man får med regulære uttrykk: man kan filtrere etter alle setninger hvor «Aftenposten» er det første ordet (^Aftenposten). Eller filtrere bort alle setninger som inneholder bokstaver ([^\w]).
Eller skifte valuta på alle beløp i hele filen. Slik kan man f.eks. skifte fra amerikansk stil (USD XXX) til norsk (XXX NOK) med et trylleslag:
Search for: USD (\d{2,4})
Replace with: $1 NOK
Dette vil si at alle forekomster av USD foran to til fire tall vil bli erstattet med de samme to til fire tallene etterfulgt av NOK.
Les mer om regulære uttrykk i dokumentasjonen til memoQ.
Oppsummert
Det var 10 av mine viktigste memoQ-triks som jeg synes gjør livet mye bedre. Nå som jeg har kjøpt lisens til programmet har jeg liksom etablert meg ugjenkallelig i memoQ-leiren, så jeg håper jeg kunne komme med noen nyttige tips til mine med-memokunister!
Memokunister, foren eder!